 StotterTheorie
StotterTheorie
StotterTheorie
StotterTheorie
Die automatische begleitende Selbstkontrolle des Sprechens, also die Prüfung, ob Wörter und Sätze korrekt und in Übereinstimmung mit der beabsichtigten Botschaft produziert wurden, bezeichne ich hier kurz als „Monitoring“. Wie experimentell nachgewiesen werden konnte [1], erfolgt das Monitoring vor allem über die Hör-Rückmeldung. Der Sprecher weiß zwar, war er sagen wollte, doch um Fehler zu erkennen, muss das Gehirn wissen, was tatsächlich gesagt wurde. Der beste Weg, an diese Information zu kommen, ist das Hören.
Willem Levelt unterscheidet in seiner Perceptual Loop Theory [2] zwischen einer äußeren und einer inneren Rückmeldung (Abbildung). Die äußere Rückmeldung (external loop) läuft über das äußere Gehör. Die innere Rückmeldung (internal loop) ist das „innere Hören“ der eigenen Worte beim stillen Lesen oder Denken. In beiden Fällen handelt es sich um eine Hör-Rückmeldung, also eine Rückmeldung in der auditiven Sinnesmodalität.
Eine wichtige Frage für die Theorie des Stotterns, die ich auf dieser Website vorstelle, ist die folgende: Sind die äußere und die innere Hör-Rückmeldung gleichzeitig aktiv? Experimente haben gezeigt, dass das nicht der Fall ist: Wenn ein von außen kommendes Sprachsignal verarbeitet wird, ist die innere Hör-Rückmeldung blockiert [3]. Das ist auch logisch plausibel, denn beides – von außen kommende Sprache einschließlich der äußeren Hör-Rückmeldung und die innere Hör-Rückmeldung – werden im selben Bereich des Gehirns verarbeitet [4].
Neben der Hör-Rückmeldung spielt für die Selbstkontrolle der Artikulation auch die taktile und kinästhetische Rückmeldung der Sprechbewegungen eine Rolle, vielleicht auch beim Registrieren phonologischer Versprecher, besonders wenn Konsonanten betroffen sind. Bei der Verursachung des Stotterns jedoch spielen die taktile und kinästhetische Rückmeldung meines Erachtens keine Rolle. Deshalb werden sie hier nur am Rande behandelt.
In zwei Punkten – die eng miteinander zusammenhängen und eigentlich ein Punkt sind – weiche ich von Levelts Modell [2] ab: Ich nehme (erstens) nicht an, dass Formulierung und Artikulation im Gehirn getrennt sind (mehr...);. Daraus folgt (zweitens), dass die innere Hör-Rückmeldung kein phonetischer Plan für das äußere Sprechen ist (mehr darüber im Abschnitt 1.5).
Warum diese Abweichung von Levelts Modell? Will man Stottern im Rahmen eines linguistischen Modells erklären, dann muss Stottern innerhalb dieses Modells möglich sein. Betrachtet man Levelts Modell unter diesem Gesichtspunkt, dann stellt sich sofort die Frage: Welches der beiden Sprachproduktions-Module – der „Formulator“ oder der „Artikulator“ – könnte in seiner Funktion gestört sein, sodass es zum Stottern kommt?
Der Formulator kann es nicht sein, denn Stotterer haben gewöhnlich kein Formulierungsproblem. Sie wissen, was sie sagen wollen und können korrekte Sätze bilden. Demnach müsste Stottern ein reines Artikulationsproblem sein. Doch auch der Artikulator scheint nicht gestört zu sein, denn beim Nachsprechen einzelner Laute und Silben, meist auch einzelner Wörter, tritt in der Regel kein Stottern auf. Auch beim Lesen im Chor oder beim Schattensprechen – Bedingungen, die keine eigene Formulierungsleistung erfordern – wird kaum gestottert.
Liegt es also am Zusammenspiel von Formulator und Artikulator? Mag sein – nur ist ein solches Zusammenspiel in Levelts Modell nicht vorgesehen: Formulator und Artikulator sind als abgeschlossene Module gedacht. Der Informationsstrom läuft nur in einer Richtung, vom Formulator zum Artikulator. Kann dieser Informationsstrom gestört sein? Kaum, denn Stotterer wissen im Moment der Blockierung immer genau, was sie sagen wollen und nicht herausbekommen.
Es ist einfach kein Platz für Stottern in einem Modell, in dem Formulierung und Artikulation strikt getrennt sind. Deshalb weiche ich in diesem Punkt von Levelt ab und nehme an, dass Formulierung und Artikulation eine Einheit bilden. Wie das geht, habe ich im vorigen Abschnitt ausgeführt: Es findet keine „phonologische Kodierung“ statt (die in Levelts Modell die Basis für die Erstellung motorischen Programme bildet), sondern die motorischen Programme für Wörter und vertraute Phrasen liegen fertig vor und müssen nur kombiniert werden. Das geschieht inkrementell (Schritt für schritt) beim Sprechen.
Äußere und innere Hör-Rückmeldung arbeiten alternierend, d.h., die innere ist nur aktiv, wenn die äußere unterbrochen ist. Das ist der Fall beim inneren Sprechen (also beim stillen Lesen und beim Denken), beim Sprechen ohne Phonation (mit stummen Sprechbewegungen), unter totaler künstlicher Vertäubung oder bei Gehörverlust.
Abbildung 3 zeigt oben die äußere und unten die innere Hör-Rückmeldung. Da ich nicht annehme, dass es getrennte Module für Formulierung und Artikulation gibt. haben beide Rückmeldeschleifen denselben Ausgangspunkt und denselben Endpunkt.
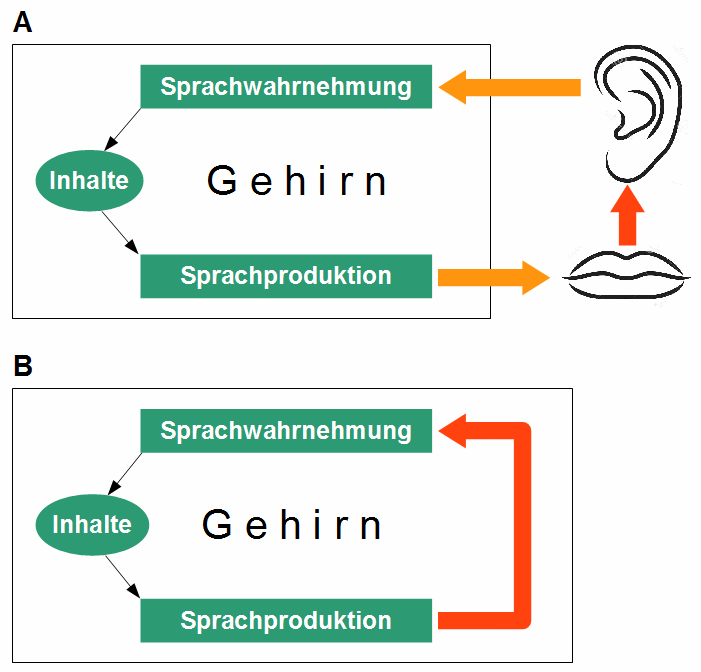
Abbildung 3: Äußere Hör-Rückmeldung (A) und innere Hör-Rückmeldung (B).
Ein prä-artikulatorisches Monitoring ist zweifellos möglich: Wir können eine Äußerung innerlich „auf Probe“ formulieren und sie überprüfen, bevor wir sie laut aussprechen. Doch wir tun das nur in Situationen, in denen wir unbedingt vermeiden müssen, etwas Falsches zu sagen, etwa bei Verhandlungen oder in einer Prüfung. Manche Stotterer verhalten sich so, um gefürchtete Wörter zu vermeiden und durch Synonyme zu ersetzen.
Im Gegensatz dazu ist das gewöhnliche, spontane Sprechen gerade dadurch gekennzeichnet, dass man seine Äußerungen nicht vor der Artikulation kontrolliert, sondern unmittelbar „seine Gedanken laut macht“, Deshalb ist Sportansprache durch häufigen Fehler und Korrekturen gekennzeichnet.
Willem Levelt [2] dagegen nimmt an, dass beim normalen Sprechen ständig ein prä-artikulatorisches Monitoring stattfindet. Er begründet dies mit vier Beobachtungen: (1) „lexical bias“: bei Versprechern entstehen selten Pseudowörter; (2) das Aussprechen von „Tabu-Wörtern“ wird spontan unterdrückt; (3) manche Sprechfehler werden schneller korrigiert, als die Hör-Rückmeldung verarbeitet werden kann; (4) eigene Fehler werden schneller erkannt als die anderer Sprecher. Ich diskutiere dieses sehr spezielle Thema im folgenden ausführlich, weil es für meine Theorie des Stotterns bedeutsam ist.
In diesen Experimenten wurden die Probanden zu bestimmten Sprechfehlern verleitet, indem sie unmittelbar vor dem lauten Lesen eines Zielwort-Paares (das gesprochen werden sollte) eine Liste mit Wortpaaren still lasen (also innerlich sprachen), die dem erwünschten Versprecher klanglich ähnlich waren (Priming-Liste). Die Priming-Liste und die Zielwort-Paare war so gestaltet, dass mit hoher Wahrscheinlichkeit in dem einen Experiment [5] Pseudowörter (Nonsens), in dem anderen Experiment [6] „Tabu-Wörter“ (die man in guter Gesellschaft nicht ausspricht) als Versprecher auftreten sollten; beides war nicht der Fall.
Die Autoren (und Levelt) schließen daraus, dass sowohl das laute Aussprechen von Nonsens als auch von Tabu-Wörtern durch ein inneres, prä-artikulatorisches Monitoring verhindert wird. Doch selbst wenn hier ein prä-artikulatorisches Monitoring stattgefunden haben sollte, nicht während des lauten Sprechens, sondern bereits vorher stattgefunden hat. Die Experimente sind also kein Nachweis für die Aktivität der inneren Hör-Rückmeldung während des lauten Sprechens.
Aber sind die beobachteten Beobachtungen überhaupt Nachweise für ein inneres prä-artikulatorisches Monitoring? Der Tendenz, dass bei Versprechern oft falsche Wörter, aber selten Pseudowörter produziert werden (lexical bias), lässt sich gut dadurch erklären, dass es für alle vertrauten Wörter motorische Programme gibt (siehe vorigen Abschnitt). Für Nonsens-Wörter gibt es solche Programme, auf die das Gehirn direkt zugreifen kann, nicht. Pseudowörter müssen aus Silben und ggf. Phonemen zusammengefügt werden, und das ist aufwendiger. Die meisten Versprecher sind Verwechslungen ähnlich klingender Wörter – und damit Verwechslungen von Wort-Sprechprogrammen.
Das Aussprechen von Tabu-Wörtern dürfte durch den selben unbewussten Mechanismus gehemmt werden, der uns auch sonst davor bewahrt, unanständige Dinge zu tun, ohne dass wir uns deswegen permanenten selbst beobachten müssen. Antonio Damasio [7] hat den Mechanismus beschrieben: Begriffe sind mit somatischen Markern verknüpft, sodass mit der Aktivierung eines Begriffes im Gehirn zugleich ein Gefühl aktiviert wird, das diesen Begriff emotional bewertet und der Verhaltenssteuerung dient. Tabu-Wörter sind mit Furcht vor Blamage oder Strafe emotional „markiert“, und das hemmt das Aussprechen dieser Wörter.
Auch die Tatsache, dass manche Fehler unmittelbar nach den Aussprechen korrigiert werden – schneller, als es über die Hör-Rückmeldung möglich wäre, ist kein Beweis für ein prä-artikulatorisches Monitoring. Heute nimmt man an, dass die Erkennung von Sprechfehlern vor der Artikulation nicht auf einer inneren sensorischen Rückmeldung basiert, sondern auf einem Konflikt-Monitoring während der Sprachproduktion, d.h., das System reagiert dabei auf die gleichzeitige Aktivierung nicht zusammen passender motorischer Programme [8].
Die Beobachtung, dass eigene Sprechfehler schneller erkannt werden als fremde, wurde in einem Experiment gemacht, in dem die Versuchspersonen Silbenfolgen wie /pi-di-ti-gi/, /pi-ö-ti-o/ oder /ö-i-o-u/ eine halbe Minute lang im Sekundentakt wiederholten. Der Takt wurde durch ein Blinklicht angezeigt [9]. Beim Erkennen eines Fehlers sollte der Sprecher bzw. der Zuhörer einen Knopf drücken. Es überrascht nicht, dass die Sprecher ihre Fehler schneller erkannten als die Zuhörer, und zwar aus zwei Gründen:
Erstens steht dem Sprecher neben der akustischen die taktile und kinästhetische Information zur Verfügung: Wenn ich z.B. ansetze, /ti/ anstatt /pi/ zu sagen, spüre ich das, ehe für einen Zuhörer etwas zu hören ist. Das gilt für alle Silben, die mit Konsonant beginnen. Schon im ersten Teil des Experiments, beim Vergleich der Geschwindigkeit der Fehler-Erkennung über die innere und äußere Rückmeldung, zeigte sich, dass es eine Rolle spielt, ob Fehler bei Konsonanten oder Vokalen auftreten. Die Selbstwahrnehmung der Artikulation ist aber gerade kein prä-artikulatorisches Monitoring.
Hinzu kommt, dass während der Sprecher seine Artikulation auch taktil und kinästhetisch wahrnimmt und deshalb genau weiß, ob er gerade /pi/ oder /ti/ gesagt hat, ist der Zuhörer allein auf sein Gehör angewiesen. Bein Hören auf stupide wiederholte Silbenfolgen wie /pi-di-ti-gi/ usw. wird er, wenn er einen Fehler gehört zu haben meint, nicht selten unsicher sein, ob er sich verhört hat und zögern, den Knopf zu drücken. Ich denke, dies beides genügt, um die längeren Reaktionszeiten der Zuhörer zu erklären – denn genau genommen wurden in dem Experiment nicht Wahrnehmungs- sondern Reaktionszeiten gemessen.
Ich ändere und ergänze Levelts Modell in folgenden Punkten: (1) Formulierung und Artikulation sind beim spontanen Sprechen eins; (2) Äußere und innere Hör-Rückmeldung sind nicht gleichzeitig aktiv; (3) beim spontanen Sprechen und normalen Hören der eigenen Rede ist nur die äußere Hör-Rückmeldung aktiv.
In Willem Levelts Modell der Sprachproduktion [1] existieren im Gehirn zwei getrennte Module: eines für die Planung der Formulierung und eines für die Planung der Artikulation. Der „Formulator“ wandelt eine präverbale Botschaft in Sprache um und erzeugt einen „phonetischen Plan“, der „Artikulator“ wandelt diesen um in eine Folge von Befehlen an die am Sprechen beteiligten Muskeln. Der Ausgangspunkt der inneren Rückmeldeschleife ist bei Levelt der Formulator, der Ausgangspunkt der äußeren Rückmeldung ist der Artikulator. Die zwei getrennten Module sind aber weder im Gehirn nachgewiesen, noch ist ihre Existenz wahrscheinlich. Ich nehme jedenfalls nicht an, dass beim spontanen Sprechen Sätze erst formuliert werden (von einem inneren Formulator – also ohne Wissen des Sprechers?) und dass sie danach artikuliert werden, sondern dass sie formuliert werden, indem sie artikuliert werden (siehe auch die nächste Fußnote). Dabei entstehen all die Formulierungsmängel und -korrekturen, die für das spontane Sprechen so charakteristisch sind.
(zurück)